- DeepSeek-OCR utiliza compresión óptica de contextos para reducir drásticamente el uso de tokens en modelos IA.
- Permite extraer y analizar texto, tablas, diagramas y estructuras visuales con precisión y máxima eficiencia computacional.
- Su carácter open source y compatibilidad con frameworks líderes lo hace flexible para startups y grandes empresas.
En los últimos tiempos, la inteligencia artificial y las tecnologías multimodales han dado un salto notable en la forma en la que interactuamos con los datos visuales y textuales. Entre las soluciones más rompedoras de este avance destaca DeepSeek-OCR, una herramienta que está revolucionando tanto la extracción inteligente de texto en imágenes como el procesamiento eficiente de información para empresas y desarrolladores. Recientemente lanzada por la innovadora compañía china DeepSeek AI y disponible como software open source, DeepSeek-OCR promete cambiar radicalmente la eficiencia en el manejo de documentos, la digitalización administrativa y el procesamiento visual avanzado, especialmente en campos como las finanzas, la investigación científica y el análisis de datos.
Frente a modelos OCR tradicionales, DeepSeek-OCR introduce una compresión óptica de contextos que aprovecha la visión por IA y los grandes modelos de lenguaje (LLM) para ofrecer precisión, rapidez y una integración multimodal sin precedentes. Desde startups que buscan optimizar costes hasta compañías tecnológicas que requieren manejar cantidades ingentes de datos con pocos recursos computacionales, DeepSeek-OCR ha desatado un interés enorme por su potencial para extraer texto, comprender estructuras como tablas o diagramas, y reducir el uso de tokens en los sistemas IA, facilitando el trabajo con documentos extensos sin incrementar la carga en hardware o servidores.
¿Qué es DeepSeek-OCR y por qué está en boca de todos?
DeepSeek-OCR es un modelo multimodal de reconocimiento óptico de caracteres (OCR) que va mucho más allá de simplemente extraer texto de imágenes. Desarrollado por DeepSeek AI, integra tecnologías de visión computacional y LLM como nunca antes, permitiendo una compresión inteligente de datos visuales a tokens textuales, optimizados para el procesamiento en modelos de IA de última generación como Transformers y vLLM.
Su principal innovación radica en cómo logra condensar la información visual en representaciones altamente compactas, transformando documentos e imágenes complejas en secuencias de tokens mucho más reducidas, pero conservando los detalles y la estructura relevante. Esto se traduce no solo en una mejora brutal en la eficiencia del uso de recursos, sino también en una ventana mucho más amplia para trabajar con documentos largos y presentaciones visuales heterogéneas.
A diferencia de las soluciones clásicas como Tesseract o PaddleOCR, DeepSeek-OCR no se limita a leer caracteres: interpreta tablas, diagramas, fórmulas matemáticas y representaciones espaciales, permitiendo una extracción de datos contextualizada y precisa, esencial en sectores donde el contexto visual es tan importante como el contenido textual.
La revolución de la compresión óptica de contextos
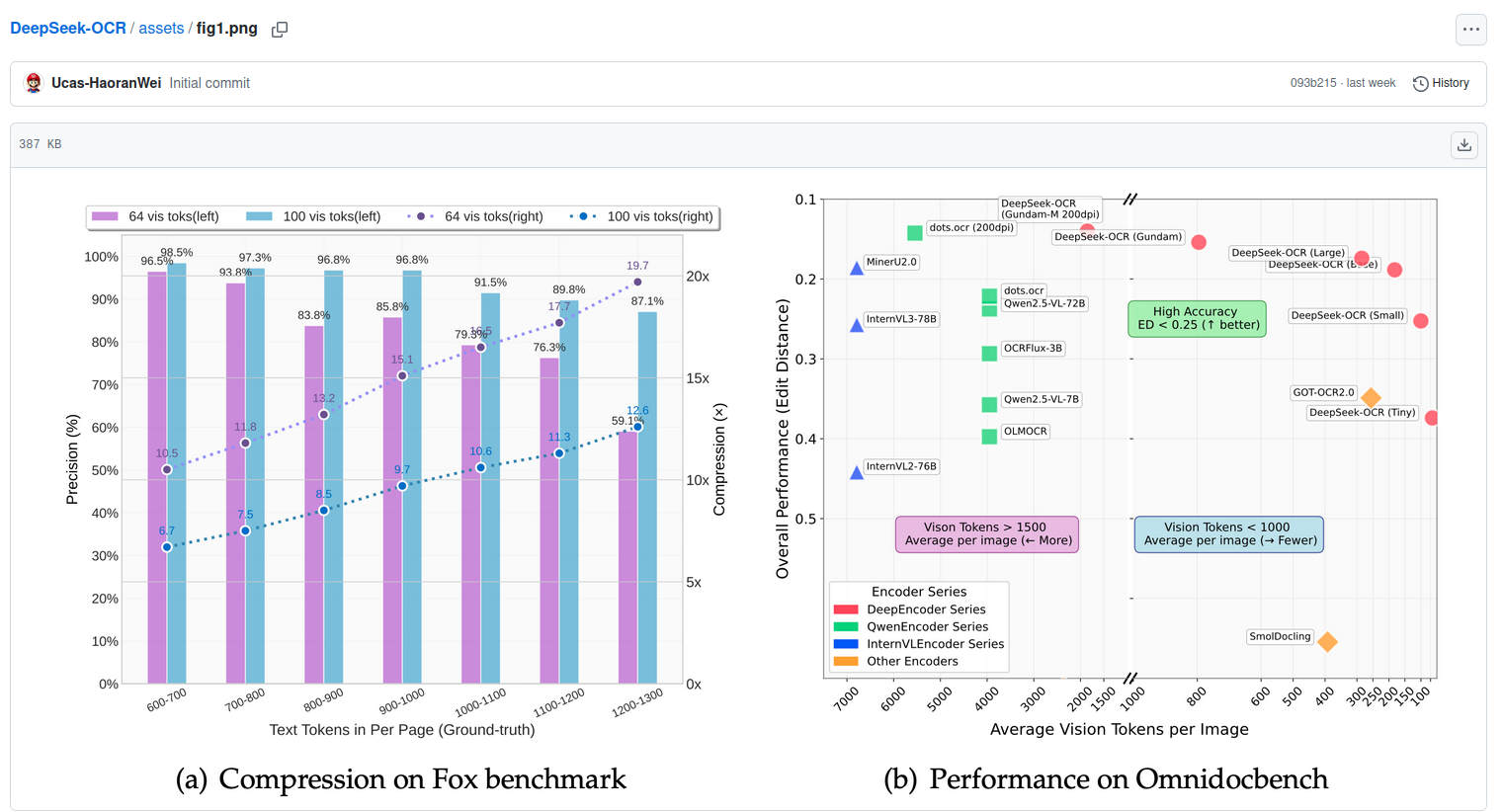
Uno de los pilares conceptuales de DeepSeek-OCR está en la compresión óptica de contextos. Hasta ahora, los codificadores visuales generaban grandes cantidades de tokens al procesar imágenes, lo que suponía un reto para las LLM por su coste computacional y limitaciones de contexto. DeepSeek-OCR invierte este paradigma: logra comprimir las entradas visuales hasta en 7 a 20 veces respecto al volumen original de texto, permitiendo que tareas antes inabordables por tamaño o coste ahora sean accesibles para cualquier empresa o equipo de desarrollo.
La técnica consiste en condensar la imagen y la información visual en una representación ultracompacta de tokens, utilizando codificadores visuales avanzados, atención multi-cabeza y mecanismos de grounding para conservar tanto el contenido textual como los matices espaciales o jerárquicos. De este modo, un documento escaneado, una hoja con gráficos o incluso un recibo digitalizado puede ser comprendido y analizado manteniendo sus relaciones internas y referencias visuales.
Esto, además, disminuye la sobrecarga de memoria y reduce drásticamente los tiempos de inferencia, lo cual es clave en entornos donde la rapidez y la escalabilidad son determinantes. Por ejemplo, en una GPU Nvidia A100-40G, DeepSeek-OCR puede procesar más de 200.000 páginas de datos de entrenamiento al día, y alcanzar velocidades de hasta 2.500 tokens por segundo procesando PDFs en escenarios de alta concurrencia.
Características avanzadas y modos de operación
DeepSeek-OCR destaca por ofrecer varios modos de resolución para adaptarse a diferentes casos de uso y recursos disponibles. Desde el modo miniatura (64 tokens para imágenes de 512×512) hasta el modo grande (400 tokens en 1280×1280), el sistema permite elegir el equilibrio perfecto entre calidad, detalle y eficiencia.
- Compresión adaptable: selecciona automáticamente el nivel de compresión ideal según el contenido de la imagen y la densidad de información.
- «Modo Gundam»: combina segmentos de imagen a distintas resoluciones, ideal para documentos complejos o de ultra alta resolución como planos arquitectónicos o libros escaneados completos.
- Grounding y referencias espaciales: integración de etiquetas especiales y mecanismos para referenciar elementos concretos en una imagen; esencial para realidad aumentada o consultas visuales interactivas.
- Transformación multimodal: puede convertir imágenes y documentos no solo a texto plano, sino también a formatos estructurados como markdown, preservando tablas, listas y jerarquías.
- Descripción contextual de imágenes: generación de subtítulos automáticos detallados, ideal para accesibilidad, clasificación o búsqueda avanzada.
Este conjunto de capacidades, junto con su compatibilidad directa con frameworks líderes como vLLM y Transformers, asegura una integración fluida en cualquier flujo de trabajo moderno de machine learning, facilitando tanto la inferencia como el entrenamiento sobre conjuntos de datos multimodales.
Beneficios para empresas, startups y desarrolladores
El carácter open source y la licencia MIT de DeepSeek-OCR otorgan a startups, pymes y grandes organizaciones una ventaja estratégica clara: acceso a una tecnología puntera con libertad total para modificar, adaptar y desplegar según sus necesidades. Esto se traduce en:
- Reducción importante de los costos de procesamiento documental, permitiendo escalar sin aumentar proporcionalmente la infraestructura.
- Escalabilidad y personalización: el modelo se puede ajustar y extender, adaptándose a casos de uso únicos y a cargas variables de trabajo.
- Automatización avanzada de procesos administrativos y legales, facilitando desde la digitalización masiva hasta la extracción inteligente de datos para análisis posterior.
- Comunidad activa y actualizaciones continuas, asegurando que el modelo evolucione rápidamente en capacidades y robustez.
El impacto real se percibe en empresas que manejan volúmenes enormes de datos visuales, donde la diferencia entre una compresión tradicional y la óptima que ofrece DeepSeek-OCR puede marcar el éxito operacional y financiero en proyectos de transformación digital.
Cómo funciona DeepSeek-OCR: Arquitectura técnica y enfoque innovador
La arquitectura de DeepSeek-OCR se asienta sobre un codificador visual con diseño optimizado para modelos LLM, empleando enfoques como Mixture-of-Experts (MoE) para incrementar la eficiencia y reducir costes computacionales. Con una base de 570 millones de parámetros, el pipeline de procesamiento sigue estos pasos:
- Preprocesamiento visual: la imagen se redimensiona, normaliza y segmenta en parches.
- Extracción de embeddings: mediante un transformador de visión, cada parche se convierte en un embedding vectorial.
- Compresión y atención: los embeddings se comprimen y refinan usando mecanismos de atención multi-cabeza, capturando relaciones visuales y referencias espaciales.
- Integración textual: los tokens visuales comprimidos se anteponen a instrucciones o prompts textuales, permitiendo un procesamiento verdaderamente multimodal.
- Grounding: utilización de tokens y módulos espaciales especiales que posibilitan consultas sobre localización exacta de componentes en una imagen.
El entrenamiento del modelo se realiza sobre enormes conjuntos de datos emparejados de imágenes y textos, con funciones de pérdida personalizadas para equilibrar compresión y fidelidad. El resultado es un modelo capaz de priorizar la información relevante, ignorando detalles redundantes, pero sin sacrificar precisión en tareas de extracción o análisis visual.
La integración con librerías como Transformers y vLLM permite aprovechar las últimas innovaciones en inferencia rápida y procesamiento batch, logrando así un rendimiento excepcional incluso en GPUs de gama alta o clusters en la nube.
Guía de instalación y recursos técnicos
Poner en marcha DeepSeek-OCR en tu entorno es un proceso accesible, incluso para quienes se inician en el mundo de la IA aplicada:
- Prepara el entorno: asegúrate de tener CUDA 11.8 y Python 3.12.9 instalados. La versión recomendada de PyTorch es la 2.6.0.
- Clona el repositorio oficial: usando
git clone https://github.com/deepseek-ai/DeepSeek-OCR.gity accede a la carpeta del proyecto. - Crea un entorno virtual: con conda (
conda create -n deepseek-ocr python=3.12.9 -yyconda activate deepseek-ocr). - Instala dependencias: incluye torch, torchvision, torchaudio y vLLM, junto con el resto de requisitos usando
pip install -r requirements.txt. - Resuelve posibles incompatibilidades: algunos errores con vLLM y Transformers pueden aparecer, pero la documentación oficial aclara cómo proceder para ignorarlos y seguir adelante.
- Descarga los pesos del modelo: disponibles tanto en Hugging Face como en el repositorio de GitHub, para facilitar la integración en cualquier pipeline existente.
Además, la documentación oficial ofrece ejemplos de uso, guías para entrenar modelos propios y recursos para adaptar DeepSeek-OCR a casos de uso finales.
Métricas de rendimiento y evaluaciones comparativas
En pruebas internas y benchmarks independientes, DeepSeek-OCR ha conseguido cifras sobresalientes en velocidad, compresión y precisión:
- Precisión: mantiene hasta un 97% de exactitud en extracción textual, incluso con compresiones inferiores a 10 veces respecto al documento original.
- Velocidad de procesamiento: alcanza más de 2.500 tokens por segundo en GPU A100-40G, superando ampliamente a otras alternativas.
- Escalabilidad: puede generar más de 200.000 páginas de entrenamiento al día, facilitando la creación y mejora de modelos internos para grandes compañías.
- Retención de detalles: los modos de mayor resolución garantizan la conservación de estructuras complejas y elementos visuales, mientras que las versiones comprimidas optimizan el uso de memoria y contexto en modelos de LLM.
- Estudios de ablación: demuestran que incluso reduciendo los tokens en un 50%, la precisión apenas disminuye un 5% en tareas de reconocimiento de texto, haciendo a DeepSeek-OCR idóneo para aplicaciones que exigen equilibrio entre calidad y recursos.
DeepSeek-OCR frente a otros modelos: comparativas clave
Comparado con competidores recientes como PaddleOCR, GOT-OCR 2.0 o MinerU, DeepSeek-OCR demuestra una ventaja consistente tanto en eficiencia de compresión como en versatilidad multimodal:
- PaddleOCR: muy eficaz en velocidad, pero menos eficiente en compresión y adaptación multimodal.
- GOT-OCR 2.0: alcanza buenos resultados en reconocimiento puro, pero no ofrece modos dinámicos ni integración avanzada con grounding.
- MinerU: destaca en minería de datos, pero carece de la capacidad de referenciación espacial puntual que ofrece DeepSeek-OCR.
- Vary: ha inspirado parte del diseño arquitectónico, pero DeepSeek-OCR da un paso más en la integración nativa con LLM y la escalabilidad de tokenización.
Las pruebas cruzadas confirman que, además de superar a estos modelos en compresión, DeepSeek-OCR mantiene o supera la precisión en contextos complejos, como imágenes manuscritas, documentos con tablas densas o gráficos multilingües.
Casos de uso y aplicaciones reales
El abanico de situaciones donde DeepSeek-OCR puede marcar la diferencia es muy amplio. Algunos de los escenarios más destacados incluyen:
- Digitalización y archivo masivo de documentos empresariales, con reducción de costes en almacenamiento y acceso rápido a la información.
- Automatización de facturación, gestión de recibos y procesos administrativos, extrayendo información clave con total fiabilidad.
- Procesamiento legal y análisis contractual, permitiendo el tratamiento de grandes volúmenes de documentación jurídica con reconocimiento de estructuras complejas.
- Investigación científica y análisis financiero, donde la interpretación de fórmulas, diagramas o anotaciones visuales es esencial para la toma de decisiones.
- Sistemas de accesibilidad y búsqueda documental, generando subtítulos y descripciones automáticas para personas con discapacidad visual o herramientas avanzadas de búsqueda y clasificación.
- Desarrollo de asistentes inteligentes, capaces de interactuar con documentos multimodales y responder consultas que requieren comprensión global de textos y gráficos.
Todo ello, junto con la disponibilidad de la herramienta en plataformas globales como Hugging Face y GitHub, impulsa su adopción en equipos internacionales y empresas de cualquier tamaño.
Un vistazo al futuro y las oportunidades de DeepSeek-OCR
La aparición de DeepSeek-OCR se inscribe en una estrategia más amplia de DeepSeek AI, que anteriormente lanzó otros modelos como V3 y R1, siempre con foco en la eficiencia, el razonamiento y el aprendizaje por refuerzo. Su obsesión por optimizar el coste del cómputo, sin sacrificar precisión ni escalabilidad, responde a una necesidad creciente en el sector tecnológico: democratizar el acceso a la inteligencia artificial de alto rendimiento y adaptarse a las regulaciones o necesidades particulares de distintas geografías, como las estrictas normativas de contenido existentes en China.
Al ofrecer su tecnología en abierto y compartir tanto los pesos del modelo como la metodología, DeepSeek AI fomenta la transparencia, la colaboración y la evolución acelerada de la IA multimodal. Esto no solo multiplica las posibilidades para empresas y organizaciones, sino que también asegura que los avances acontecidos en China y Asia puedan competir globalmente y enriquecer el ecosistema internacional de investigación y desarrollo.
DeepSeek-OCR redefine el estándar del procesamiento visual-textual en IA, permitiendo una automatización documental inteligente, eficiente y flexible, respaldada por una arquitectura técnica vanguardista y una comunidad global que empuja sus límites día a día.
Expertos en software, desarrollo y aplicación en industria y hogar. Nos encanta sacar todo el potencial de cualquier software, programa, app, herramienta y sistema operativo del mercado.